Data Augmentation이란
Image Data Augmentation
Image Data augmentation에 대한 설명을 단 뒤 이를 오디오에 적용하는 대략적인 설명을 달겠습니다.
아래의 내용은 http://nmhkahn.github.io/CNN-Practice 에서 가져왔습니다.
Data augmentation은 CNN의 성능을 높이기 위해 사용하는 방법이다. 위 그림과 같이 학습(혹은 테스트) 이미지를 디스크에서 읽은 후, 이미지를 여러 방법을 통해 변형(transform) 한 뒤에 네트워크의 입력 이미지로 사용하는 방식이다. 만약 고양이 이미지에서 모든 픽셀을 오른쪽으로 1칸 이동하여도 사람의 눈에는 같은 이미지로 보인다. 하지만 컴퓨터는 이미지를 픽셀 벡터의 형태로 표현하고 인식하기 때문에 1픽셀씩 이동한 고양이 이미지는 원본 이미지와 다른 것으로 인식하게 된다. 이를 해결하기 위해 data augmentation을 사용하는 것이다.
다시 정리하자면 data augmentation은 이미지의 레이블을 변경하지 않고 픽셀을 변화 시키는 방법이며, 변형된 데이터를 이용하여 학습을 진행한다. 또한 AlexNet부터 지금까지 거의 모든 네트워크들이 data augmentation을 사용하는 등, 매우 보편적으로 사용되는 방법이다. 그럼 data augmentation은 어떤 방법을 사용하여 이미지를 변형하는지 알아보자.

위의 그림처럼 flip을 하더라도 똑같은 고양이에 대한 데이터이므로 학습에 사용할 수 있는 data는 늘어나게 됩니다.
Audio Data Augmentation
Audio Data augmentation에 대한 아래의 커널은 https://www.kaggle.com/CVxTz/audio-data-augmentation 의 커널을 그대로 사용하였으며 추가적인 설명을 달았습니다.
audio에 대해서는 다음과 같은 방법들을 사용할 수 있습니다.
- shift : audio data를 약간 밀어줍니다. 주어진 data set은 모두 5초인데 audio event가 시작되는 부분이 조금 바뀐다고 해도 같은 event란 사실은 바뀌지 않으므로 이 방법을 사용할 수 있습니다.
- adding noise : noise를 추가하여 줍니다. white noise를 약간 추가하여 잡음에 대해서 강인한 모델을 학습할 수 있습니다.
- stretching : audio data의 빠르기를 조정하여 augmentation할 수 있습니다. 다만 빠르기를 너무 조절 할 경우에는 좋은 결과를 얻을 수 없습니다.
아래의 코드들은 Tensorflow speech recognitinon challenge에서 사용된 dataset에 진행된 코드입니다. 경로는 dataset에 맞게 바꿔놨으나 수정이 필요합니다.
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
from subprocess import check_output
print(check_output(["ls", "./esc_10"]).decode("utf8"))
# Any results you write to the current directory are saved as output.
chainsaw
clock_tick
crackling_fire
crying_baby
dog
helicopter
rain
rooster
sea_waves
sneezing
## Data augmentation definition :
- Data augmentation is the process by which we create new synthetic training samples by adding small perturbations on our initial training set.
- The objective is to make our model invariant to those perturbations and enhace its ability to generalize.
- In order to this to work adding the perturbations must conserve the same label as the original training sample.
- In images data augmention can be performed by shifting the image, zooming, rotating …
- In our case we will add noise, stretch and roll, pitch shift …
#Import stuff
import numpy as np
import random
import itertools
import librosa
import IPython.display as ipd
import matplotlib.pyplot as plt
%matplotlib inline
def load_audio_file(file_path):
input_length = 44100*5
data = librosa.core.load(file_path,sr=44100)[0] #, sr=16000
if len(data)>input_length:
data = data[:input_length]
else:
data = np.pad(data, (0, max(0, input_length - len(data))), "constant")
return data
def plot_time_series(data):
fig = plt.figure(figsize=(14, 8))
plt.title('Raw wave ')
plt.ylabel('Amplitude')
plt.plot(np.linspace(0, 5, len(data)), data)
plt.show()
data = load_audio_file("./esc_10/dog/1-30226-A-0.wav")
plot_time_series(data)
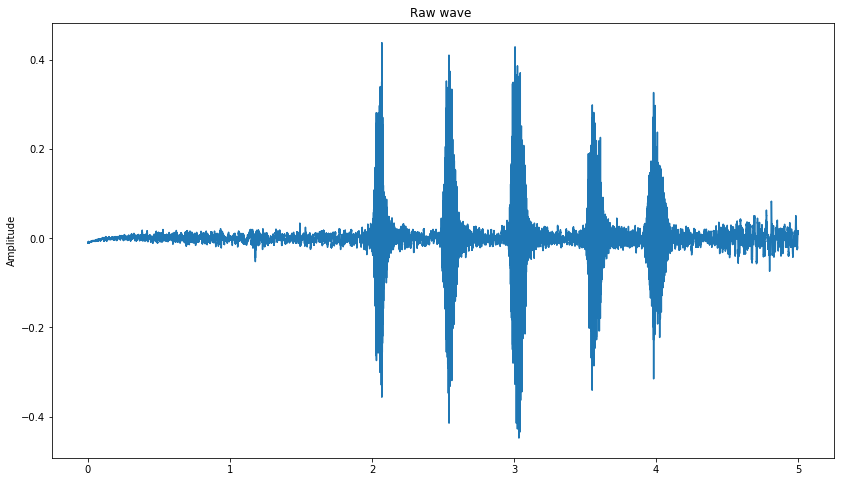
#Hear it !
ipd.Audio(data, rate=44100)
White Noise 추가
아래의 코드를 통해서 추가할 수 있습니다. 여러분이 실습시간에 배운 librosa library로 구현 가능합니다.
# Adding white noise
wn = np.random.randn(len(data))
data_wn = data + 0.005*wn
plot_time_series(data_wn)
# We limited the amplitude of the noise so we can still hear the word even with the noise,
#which is the objective
ipd.Audio(data_wn, rate=44100)
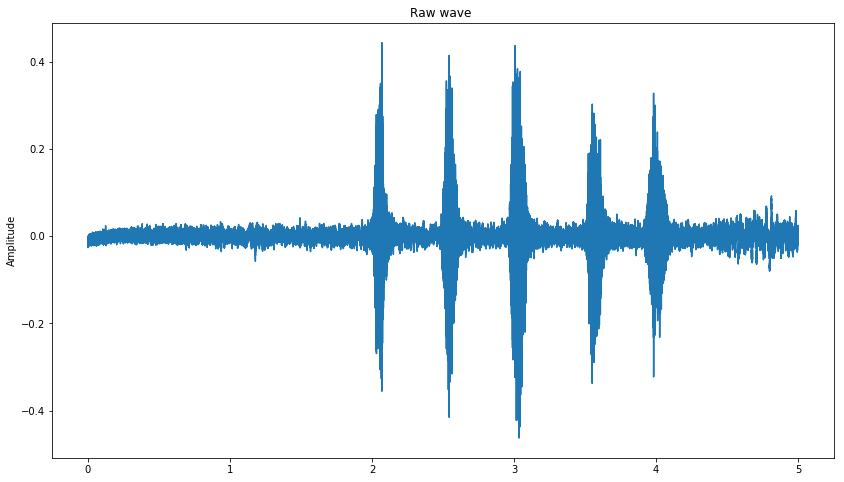
Shifting
np.roll 함수는 matrix를 rotate시키는 기능을 갖습니다. 5000으로 코드를 작성해두었는데 5000프레임들을 밀어준다고 생각하시면 됩니다.
# Shifting the sound
data_roll = np.roll(data, 5000)
plot_time_series(data_roll)
ipd.Audio(data_roll, rate=44100)
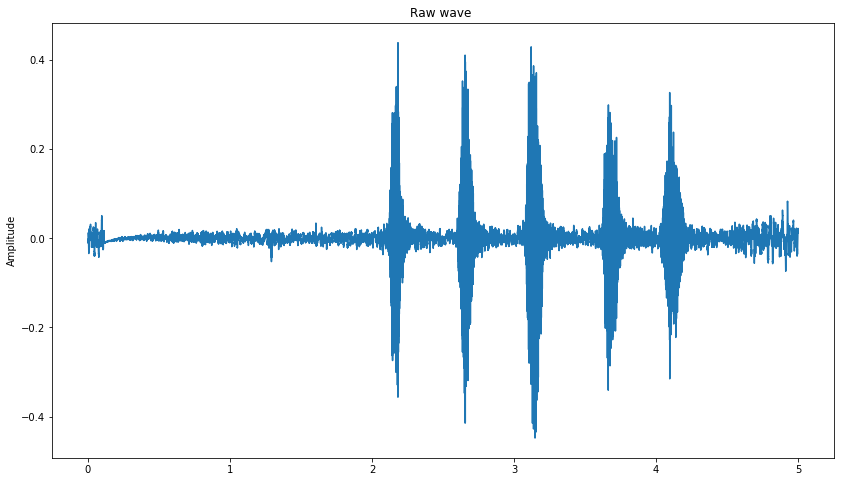
Streching
stretch 함수의 rate가 1보다 작으면 느려지고, 1보다 크면 빨라집니다.
원래 코드는 0.8과 1.2로 되어있는데 듣기에는 별차이가 없어서 조금 수치를 조정했습니다.
학습시에는 일정 범위내에서 듣기에 정상일 정도로 바꿔주세요.
# stretching the sound
def stretch(data, rate=1):
input_length = 44100*5
data = librosa.effects.time_stretch(data, rate)
if len(data)>input_length:
data = data[:input_length]
else:
data = np.pad(data, (0, max(0, input_length - len(data))), "constant")
return data
data_stretch =stretch(data, 0.5)
print("This makes the sound deeper but we can still hear 'cat' sound ")
plot_time_series(data_stretch)
ipd.Audio(data_stretch, rate=44100)
This makes the sound deeper but we can still hear 'cat' sound
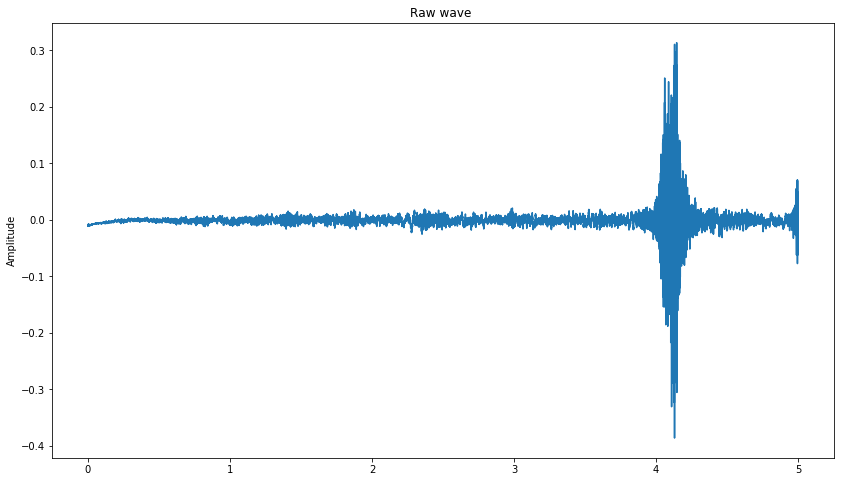
data_stretch =stretch(data, 2.0)
print("Higher frequencies ")
plot_time_series(data_stretch)
ipd.Audio(data_stretch, rate=44100)
Higher frequencies
You can now plug all those transformations in your keras data generator and see your LB rank go up :D